Modernes Monitoring: Observability als Denkweise

(Bild: iX)
Bei Observability liegt der Fokus oft auf neuen, coolen Tools. Jedoch fehlt zur erfolgreichen Umsetzung meist eher die passende Denke.
Den Begriff Observability in seiner heutigen Form gibt es noch gar nicht so lange. Populär wurde er vor allem mit dem Aufkommen von Microservice-Architekturen. Klassisches Monitoring war nicht mehr ausreichend, um diese verteilten, oft komplexen Systemen zu verstehen und Probleme nachzuvollziehen. Aus dieser Erkenntnis haben sich neue Methoden entwickelt, die der gesteigerten Komplexität verteilter Systeme entgegentreten und diese beherrschbar machen. Kommt es zu Fehlern, sollen Admins diese nicht nur entdecken, sondern auch ihre Ursache verstehen. Neben den reinen technischen Lösungen hat sich mit Observability auch eine neue Denkweise etabliert, in der Systeme nicht mehr nur von außen als Blackbox betrachtet werden. Stattdessen wagen die Verantwortlichen einen Blick ins Innere, um das Verhalten besser zu verstehen und auch vorherzusagen.
Anders als klassisches Monitoring, das primär im Bereich Operations aufgehängt ist, hat Observability einen deutlich größeren Einfluss auch auf Entwicklerinnen und Entwickler. Sie müssen einen sinnvollen Blick in das Innere der Anwendungen nicht nur ermöglichen, sondern auch bewerten. Und sie müssen entscheiden, welche Teile denn wirklich einer Beobachtung von außen wert sind. Mit dieser neuen Verantwortung sollten sich Entwickler die verschiedenen Facetten von Observability etwas genauer anschauen. Je mehr sie die deren Denkweise verinnerlichen, desto besser lässt sich eine Anwendung auch beobachten.
Die Säulen von Observability
Observability wird oft in drei Säulen aufgeteilt: Logs, Metriken und Tracing. Logs halten fest, was die Anwendung gerade tut oder gleich tun wird. Je nach Anzahl der Logs und ihres Detailgrads erlauben sie einem Außenstehenden Einblick in das Verhalten der Anwendung. Klassischerweise besteht eine Log-Nachricht aus einer oder mehreren Zeilen an Text. Früher war dieser Text meist unstrukturiert und folgte keinem festen Schema. Insbesondere durch Observability hat sich das strukturierte Logging etabliert, bei dem neben dem Text zusätzliche Daten anhängen. Diese Struktur vereinfacht es, Korrelationen zwischen verschiedenen zusammenhängenden Log-Nachrichten anhand beliebiger Metadaten zu finden, und sie ermöglicht, das Verhalten auch in einer verteilten Anwendung chronologisch besser nachzuvollziehen. Die Filterung und Aggregation von Logs wird durch strukturiertes Logging ebenfalls deutlich vereinfacht.
Metriken haben in der Vergangenheit für Entwicklerinnen und Entwickler häufiger eine kleinere Rolle gespielt. Metriken sind Messungen von wichtigen Eigenschaften, meist über einen gewissen Zeitraum. So lässt sich in einer Metrik etwa festhalten, wie viele HTTP-Anfragen die Anwendung pro Stunde verarbeitet oder wie lange bestimmte SQL-Abfragen im Schnitt dauern. Die Erfassung von Metriken erfolgt oft außerhalb der Anwendung (zum Beispiel durch einen Load-Balancer), innerhalb externer Systeme (oft der Datenbank), in Bibliotheken oder in Frameworks. Diese für Entwickler zuvor unsichtbare Erfassung von Metriken beschränkt sich meist auf sehr allgemeine Messwerte. Dass Entwicklerinnen und Entwickler nun eigene, anwendungsspezifische Metriken mit einbeziehen, nimmt in jüngster Zeit deutlich zu und stellt einen wichtigen Teil von Observability dar.

Wie Observability, Platform Engineering und andere neue Ansätze Entwicklerinnen und Entwicklern über den gesamten Software Development Lifecycle hinweg zu produktiverem Arbeiten verhelfen, zeigen die Artikel des neuen Sonderheftes iX Developer "Cloud Native" [1].
Die dritte Säule, das Tracing, ist eine strukturierte Variante von Logging, die sich bewusst an logischen Abschnitten der Anwendungsausführung orientiert und dabei Ausführungsdauer und andere Informationen aufzeichnet. Anders als bei Logging berücksichtigt das Tracing die oft hierarchische Natur von Software, sodass sich im Trace ablesen lässt, aus welchen Teilabschnitten sich ein großer Ausführungsblock zusammensetzt. Ein Abschnitt kann dabei etwa ein Funktionsaufruf, eine HTTP-Anfrage oder ein SQL-Query sein. Traces und darin enthaltene Abschnitte sind nicht auf einzelne Services beschränkt, sondern können über Netzwerkgrenzen hinweg aufgebaut werden. So lässt sich das Verhalten verteilter Anwendungen sehr gut analysieren, Abbildung 1 zeigt die typische Visualisierung eines solchen Trace. Ähnlich wie bei Metriken gibt es die Möglichkeit, Traces ohne großen manuellen Aufwand automatisch zu erfassen, was auch als automatische Instrumentierung bezeichnet wird. Ein manuelles Erfassen ist jedoch ebenfalls möglich.
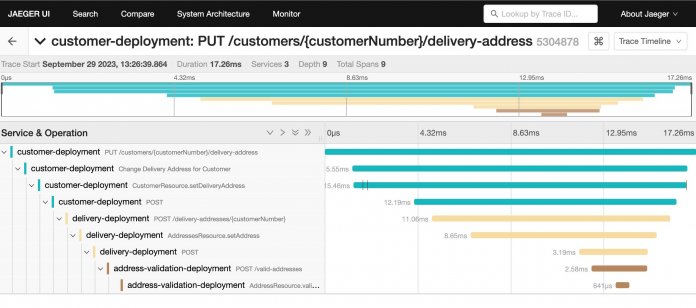
Diese drei Säulen stellen ein solides Fundament für Observability dar und liefern einen guten Überblick über die Verhaltensweise von Anwendungen im Betrieb. Auch wenn es die Meinung gibt, dass Profiling oder ähnliche Informationen ebenso ein wichtiger Bestandteil von Observability sein sollten, sind Logs, Metriken und Traces allgemein als Eckpfeiler anerkannt.
Monitoring vs. Observability
Vor Observability und natürlich auch vor DevOpsl ag der Betrieb und das dazugehörige Monitoring im Verantwortungsbereich von Operations. Hier und dort mussten Programmierer im Framework vielleicht ein paar Schalter aktivieren, damit Admins Metriken auslesen konnten, aber ansonsten beschränkte sich die Zuarbeit weitgehend auf die Ausgabe von Log-Nachrichten.
Mit dem Monitoring kann Operations feststellen, dass etwas nicht funktioniert, zum Beispiel eine Anwendung vermehrt mit Fehlercodes antwortet oder ein SQL-Query deutlich zu lange braucht. Insbesondere Metriken helfen schnell zu erkennen, dass etwas nicht ganz so rund läuft wie erwartet. Operations kann die tatsächliche Ursache jedoch nur schwer erkennen, wenn das Problem nicht in der Infrastruktur, sondern in der Anwendung selbst liegt. Für das Monitoring ist die Anwendung zu großen Teilen eine Black Box, deren inneres Verhalten verborgen bleibt.
Selbst die von Entwicklern ausgegebenen Logs, die einen Teil des inneren Verhaltens offenlegen könnten, helfen Operations selten zur Erkenntnis der tatsächlichen Ursache. In der Praxis geben Admins diese Probleme meist an die Entwickler weiter, damit diese die Ursache analysieren und eine Lösung finden – nicht selten mit dem berechtigten Kommentar, dass ja sinnvolle Log-Nachrichten fehlen.
Das ist nicht allzu verwunderlich, da Entwicklerinnen und Entwickler häufig beim Erstellen der Log-Ausgaben weniger an den Betrieb denken, sondern an die Arbeit am Sourcecode . Auch wenn die Entwickler bewusst Log-Ausgaben für den Betrieb anlegen, ist es für sie schwer abzuschätzen, was wirklich hilfreich ist, um die Ursachen eines Problems schnell zu erkennen. Sinnvolle Log-Ausgaben entstehen meist erst dann, wenn bereits in der Vergangenheit ein Fehler an ähnlicher Stelle der Anwendung aufgetaucht ist.
Insbesondere wenn ein Problem mehrschichtig ist und seine Ursache ihre Wurzeln in Infrastruktur und Anwendung hat, stößt eine strikte Trennung zwischen Operations und Entwicklung schnell an Grenzen. Observability versucht, Anwendungen als White Boxes zu betrachten und sowohl Operations als auch Entwickler (sowie weitere relevante Stakeholder) daran zu beteiligen.
Zudem ist Monitoring eher reaktiv, während Observability deutlich proaktiver zum Einsatz kommen kann. Die Teams können jeden Vorfall als Gelegenheit nutzen, die Anwendung robuster zu gestalten, da sie die Ursache bis in die Tiefe hinein verstehen. Wenn Operations und Entwickler an einem Strang ziehen, bietet Observability gegenüber dem klassischen Monitoring enorme Mehrwerte.
Inhaltliche und technische Brille
Gerade durch den gesamtheitlichen Blick, den Observability als Denkweise mit sich bringt, rücken inhaltliche Aspekte in Anwendungen deutlich stärker in den Vordergrund. Nicht nur Metriken, Logs oder Traces spielen eine Rolle, sondern gerade auch inhaltliche Informationen, die wichtig sein können, um ein System sinnvoll zu beobachten. Rein technische Eindrücke können umgekehrt tatsächliche Probleme kaschieren. Wenn Entwickler beispielsweise keinen entsprechenden Fehlercode gesetzt haben und in einem Shop das Abschicken der Bestellungen nicht funktioniert, würde dies eine technische Metrik nicht erkennen. Einer inhaltlichen, die die Bestellabschlüsse pro Stunde anzeigt, wäre dieses Problem hingegen schnell aufgefallen.
Um das Potenzial vollständig auszuschöpfen, ist es daher notwendig, sowohl die technische als auch die inhaltliche Brille aufzusetzen. Das gilt beim Sammeln von Informationen (Logs, Metriken oder Traces) ebenso wie bei der Beobachtung im laufenden Betrieb. Nicht jede inhaltliche Metrik ist für einen technischen Experten interpretierbar, genauso wenig wie eine technische Metrik für Kenner der Inhalte. Gerade Entwicklerinnen und Entwickler, die sowohl die technische als auch die inhaltliche Seite der Anwendung im Blick haben, können einen guten Dienst leisten, indem sie sinnvolle inhaltliche Informationen für die Observability sammeln.
In der Praxis empfiehlt es sich, bereits bestehende Informationen um inhaltliche Aspekte anzureichern. Bei Log-Nachrichten ist es hilfreich, statt diese nur mit technischen Metainformation wie der Thread- oder Request-ID anzulegen, auch Informationen wie Produkt-ID oder den Namen des Anwendungsfalls mitzugeben. So kann beim Durchforsten von Logs sowohl die Filterung anhand der Request-ID als auch der Produkt-ID Sinn ergeben.
In gängigen Observability-Werkzeugen ist es vorteilhaft, verschiedene Sichten auf Informationen zu visualisieren. Produktmanager werden deutlich mehr von einem inhaltlich fokussierten Dashboard profitieren – Admis von einem technischen. Da bei Visualisierungen der Observability weniger oft mehr ist, bietet diese zielgruppengerechte Aufteilung Vorteile.
Observability leben
Damit Observability auch wirklich funktioniert, müssen alle Beteiligten die damit verbundene Denkweise übernehmen. Ohne jemals überhaupt einen Trace gesehen zu haben, wird es sehr schwer zu verstehen, was einen guten Trace ausmacht und welche Informationen in der Anwendung gesammelt werden sollten.
Je mehr Entwicklerinnen und Entwickler in den Betrieb eingespannt sind, desto mehr Verständnis haben sie für die Notwendigkeit aussagekräftiger Logs, Metriken und Traces. Hier hat die DevOps-Bewegung in den letzten Jahren schon gute Vorarbeit geleistet. Alle Entwicklerinnen und Entwickler sollten in der Lage, aber auch willens sein, zu einer wirksamen Observability beizutragen.
Bereits während der Entwicklung stellen Observability-Tools eine große Hilfe dar. Sie sollten auch lokal auf den Maschinen der Entwickler laufen, sodass diese die gesammelten Informationen genau auf dieselbe Weise sehen, wie Operations und Co. später im produktiven Betrieb. Wenn sie bereits während der Entwicklung diesen Blickwinkel einnehmen, ist es für sie einfacher, bessere Logs zu schreiben, sinnvollere Metriken zu finden und passend Traces zu erweitern. Hinzu kommt, dass Observability die Entwicklung selbst unterstützt, indem zum Beispiel eine Log-Nachricht einen Logik-Fehler aufdeckt, eine Metrik redundante Aufrufe aufzeigt oder ein Trace eine langsame SQL-Query sichtbar macht. Dies stellt gewissermaßen die Anwendung der Dev-Prod-Parity aus der 12-Factor-App dar (siehe dazu den Artikel "Verteilte Anwendungen" auf Seite !!!) und zielt darauf ab, dass das gesamte Team die Observability möglichst zu jeder Zeit ähnlich behandelt, sei es lokal auf der Dev-Stage oder live in der Produktion.
Die Entscheidung, eine bestimmte Library, ein Framework, eine neue Datenbank oder ein sonstiges externes System zu verwenden, liegt meist in den Händen der Entwickler, selbst dann, wenn andere sich später um Wartung und Betrieb kümmern. Dabei findet häufig zu wenig Berücksichtigung, wie passend die gewählten Systeme für Observability sind. Jedoch sollte die Denkweise hier eine andere sein: Für jede neue Technologie sollten alle Beteiligten bereits zu Beginn überlegen, welche sinnvollen Logs sich ausgeben lassen, welche Metriken besonders wichtig sind und wie ihr Beitrag zum Tracing sein könnte. Jedes System, das nicht "observable" ist oder gemacht werden kann, stellt ein Risiko dar, wenn es später darum geht, bei unweigerlich auftretenden Fehlern die eigentliche Ursache zu erkennen. Observability sollte daher durchaus Einfluss auf Technologieentscheidungen und die Architektur von Anwendungen haben.
Grenzen der Observability
Jedem Beteiligten sollte speziell beim Verwenden von Metriken und Traces bewusst sein, dass in der Regel nur als Stichprobe in den Observability-Tools ankommen (Sampling). Die Analyse- und Visualisierungstools werten nicht jede Messung oder jeden Trace auch tatsächlich aus. Gerade bei feingranularen Metriken oder detaillierten Traces fallen enorme Datenmengen an, deren Speicherung bereits nach kurzer Zeit auch finanziell kaum tragbar ist. Unter der Annahme des Gesetzes der großen Zahlen mildert Sampling dieses Problem und sorgt gleichzeitig dafür, dass immer noch aussagekräftige Ergebnisse entstehen.
Während sich Sampling in der Praxis bewährt hat, ergeben sich daraus jedoch einige Konsequenzen. Zwar sollten möglichst alle wichtigen Informationen festgehalten werden, aber für Metriken und Traces gibt es anders als bei Logs kein den Log Levels vergleichbares Konzept. Es muss immer berücksichtigt werden, ob es sich lohnt, eine spezielle Information zu sammeln oder nicht, sodass es oft einem Balanceakt entspricht, das richtige Maß an Details zu finden.
Sampling bedeutet auch, dass insbesondere Traces kein gutes Mittel zum Debuggen einzelner Ereignisse sind, denn Stichproben tendieren dazu, seltene Ereignisse nicht zu erfassen. Diese lassen sich daher häufig nur in den Logs analysieren. Entwicklerinnen und Entwickler sollten daher versuchen, wichtige Informationen nicht nur an Traces zu hängen, sondern gleich in entsprechende Logs mitzugeben. Auch wenn der ausschließliche Einsatz von Traces verlockend ist, kann dies zumindest in heute gängigen Systemen problematisch sein. Traces dienen vor allem dazu, ein Gefühl dafür zu bekommen, wie eine Anwendung sich im Schnitt verhält, während Logs die Möglichkeit bieten, jede einzelne Situation für sich zu analysieren. Einen alternativen Ansatz auf Basis von eBPF behandelt der Artikel "Debugging in Produktion" auf Seite !!!.
Zukunft von Observability
Die drei Säulen von Observability werden häufig sehr isoliert betrachtet, sodass es wenig Berührungspunkte zwischen ihnen gibt. Gerade gängige Visualisierungs- und Analyse-Tools zeigen sie meist in separaten Ansichten. Allmählich setzt sich jedoch die Erkenntnis durch, dass enorme Mehrwerte entstehen, wenn Metriken, Traces und Logs miteinander korreliert werden können.
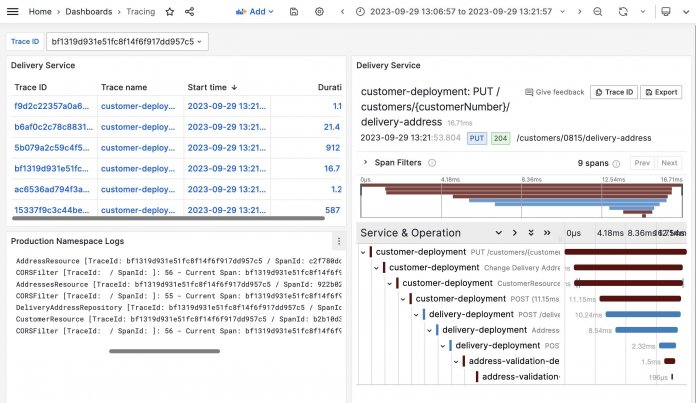
Zeigt etwa eine Metrik an, dass Anfragen in großer Häufigkeit einen Fehler zurückgeben, ist sinnvoll, so schnell wie möglich zu den relevanten Traces springen zu können. Hier erkennen Admins meist schnell, in welchem Teilabschnitt der Anwendung der Fehler auftritt. Anschließend ist es hilfreich, wenn das Tool direkt alle relevanten Log-Nachrichten für diesen Teilabschnitt anzeigt. Abbildung 2 stellt eine mögliche Umsetzung dieser Idee dar. Auch ein rasches Wechseln zwischen den Traces ermöglicht das schnelle Betrachten möglichst vieler relevanter Log-Nachrichten. Andere Korrelationen betreffen etwa eine inhaltliche Eigenschaft wie die Produkt-ID, über die sich sowohl alle Logs als auch Traces finden lassen.
Eine Verbindung zwischen den drei Säulen bringt enorme Vorteile und hat Einfluss auf Entwicklungsteams. Denn wie und welche Informationen Entwicklerinnen und Entwickler sammeln, hängt davon ab, wie Admins sie später verwenden. Zu wissen, dass Tools Logs anhand eines Trace oder anders herum anzeigen, führt möglicherweise dazu, dass die Entwickler andere Log-Nachrichten ausgeben oder die Granularität von Traces variieren. Hier fehlen in der Praxis leider noch Erfahrungswerte. Dennoch sollte den Teams bewusst sein, dass Observability sich in diese Richtung entwickelt.
Fazit
Der Artikel hat bewusst wenig über Tools geredet – mehr dazu findet sich in den Beiträgen auf den folgenden Seiten der Rubrik Observability. Zu oft verlieren sich Entwicklerinnen und Entwickler in den Werkzeugen, obwohl Observability zu großen Teilen eher als Denkweise zu verstehen ist – eine, die insbesondere auf die ganzheitliche Beobachtung von Anwendungen zielt. Sowohl die technische, aber auch die inhaltliche Seite sind wichtig, um das Verhalten – und insbesondere das Fehlverhalten – von Anwendungen zu verstehen. Observability dient aber nicht nur zur Fehlererkennung. Viel mehr will sie auch Fehler vermeiden, entweder durch frühzeitige Erkennung oder durch Beheben der eigentlichen Ursachen, die meist die Observability überhaupt erst als solche erkennen lässt.
Renke Grunwald
ist seit 2014 bei Open Knowledge als Head of Cloud Solutions tätig und berät Kunden rund um das Thema Cloud. Dabei fühlt er sich sowohl im Frontend als auch im Backend wohl.
(who [2])
URL dieses Artikels:
https://www.heise.de/-9324670
Links in diesem Artikel:
[1] https://www.heise.de/news/iX-Developer-Cloud-Native-ist-da-9357842.html
[2] mailto:who@heise.de
Copyright © 2023 Heise Medien